V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs
We introduce V*, an LLM-guided visual search mechanism that employs the world knowledge in LLMs for efficient visual querying. When combined with an MLLM, this mechanism enhances collaborative reasoning, contextual understanding, and precise targeting of specific visual elements. This integration results in a new MLLM meta-architecture, named Show, SEArch, and TelL (SEAL).
A salient aspect of human cognitive reasoning process involving visual information is the ability to conduct visual search - the process of efficiently recognizing and localizing key objects within intricate real-world scenes. This mechanism plays a fundamental role in the interaction with the environment and happens everywhere, from finding keys on a cluttered table to searching for a friend in the crowd. Besides, it is also an indispensable step for complex tasks that require multiple reasoning steps. The intricacy of visual search has been studied for a long time in cognitive science and vision science
Multimodal LLMs (MLLMs)
Our proposed Show, Search and Tell (SEAL) framework is a general meta-architecture for MLLMs. It is comprised of a VQA LLM and a visual search model which collaborate and interact through the visual working memory (VWM). In this work, we provide an instantiation of SEAL to validate its effectiveness and choose the LLaVA-7B model as the MLLM in the SEAL framework.
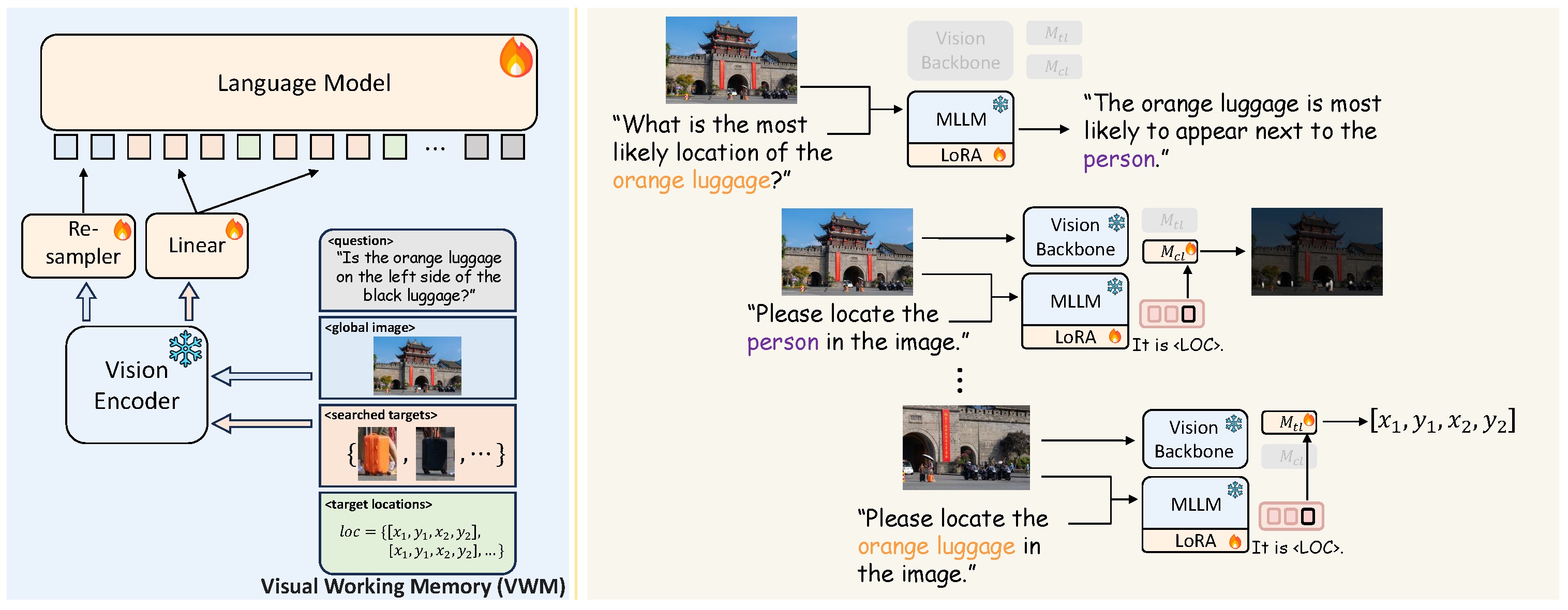
The visual search mechanism is not always engaged. The VQA LLM first evaluates if the encoder's initial (global) visual features suffice for answering the question. If not, it explicitly lists all the needed but missing information in the format of a list of target objects. Then, it initializes a visual working memory (VWM). The VWM has four blocks, the <question> block contains the initial textual question; <global image> contains the initial image; <searched targets> stores the target object crops after search; and <target location> stores the coordinates of the searched targets. Next, the visual search model searches over the image and localizes each required target. A region containing the identified target is then cropped from the whole image. The cropped targets, along with their coordinates, are added to the VWM. After that, the VQA LLM processes the data contained in the VWM to generate the response accordingly.
Similar to how people often zoom in on their phones for a clearer view, when dealing with a high-resolution image, it's possible that the target object cannot be precisely identified and located if only the entire image is viewed as a small thumbnail.To address this, one straightforward approach is to patchify an image into uniformly sized small patches and perform the localization on each patch exhaustively. This brute-force strategy tends to be too inefficient for effectively managing images with very high resolutions -- we need a smarter solution.
Drawing inspiration from how humans utilize contextual scene and top-down feature guidance in their visual search process, we've incorporated similar concepts into the design of the visual search model in V*. This process utilizes an MLLM that encapsulates a vast amount of common sense knowledge, serving as heuristic guidance. In order to localize and crop the searched targets for VWM, it's also necessary to enhance the MLLM with additional localization capabilities.
With this visual search model, our V* algorithm works as follows. Given an image and a textual expression of the target object, the V* MLLM first attempts to locate the target directly. In this step, we obtain the target localization results (coordinates and confidence) and the search cue heatmap. When no object is located (the confidence score falls below a threshold), we scrutinize the search cue heatmap for possible target-specific cues.
The search cue heatmap highlights regions that could potentially contain the queried target object. When the target-specific cue is prominent (ie. when the highest value in the heatmap exceeds the threshold \(\delta\)), we use it to guide the search directly. Otherwise, we ask the MLLM what is the most likely location of the target object in the image. This requires the MLLM to utilize its common sense knowledge and integrate it with the image's context to provide the contextual cue about the target's whereabouts. Upon receiving a description of the region where the target object is likely located, we prompt the MLLM to locate the described area and produce a search cue heatmap corresponding to the contextual cue.
Then, we use a simple strategy and recursively divide the image into 4 non-overlapping equal-sized patches. Subsequently, we assign search priority scores to these patches. The search priority score is calculated from the search cue heatmap (either target-specific or contextual). Based on the priority scores, the patches are then cropped and processed sequentially. This recursive procedure is repeated until the target object is located or the size of the current patch becomes smaller than a predetermined threshold.

The naming of our LLM-guided visual search V* algorithm is inspired by its similarities to the informed search algorithm A*. A* is designed for pathfinding, aiming to identify the shortest route between a starting point and a goal by using a heuristic to approximate the cost. In the context of our LLM-guided visual search, V* can be seen as a unique variant of A*, where sub-images are treated as nodes. The cost function \(g(n)\) is set as a uniform positive constant for all \(n\) and the heuristic function \(h(n)\) is defined as the negative of the priority score derived from the search cue heatmap. While the A* algorithm's objective is to find a path with minimal cost from start to goal, our focus with V* is solely on minimizing the total number of steps required to locate the goal.
To quantitatively evaluate MLLMs' ability in challenging scenarios where the image contains abundant and complex information and the visual information needed might not be easily found, we build a benchmark V*Bench based on 191 high-resolution images from SAM 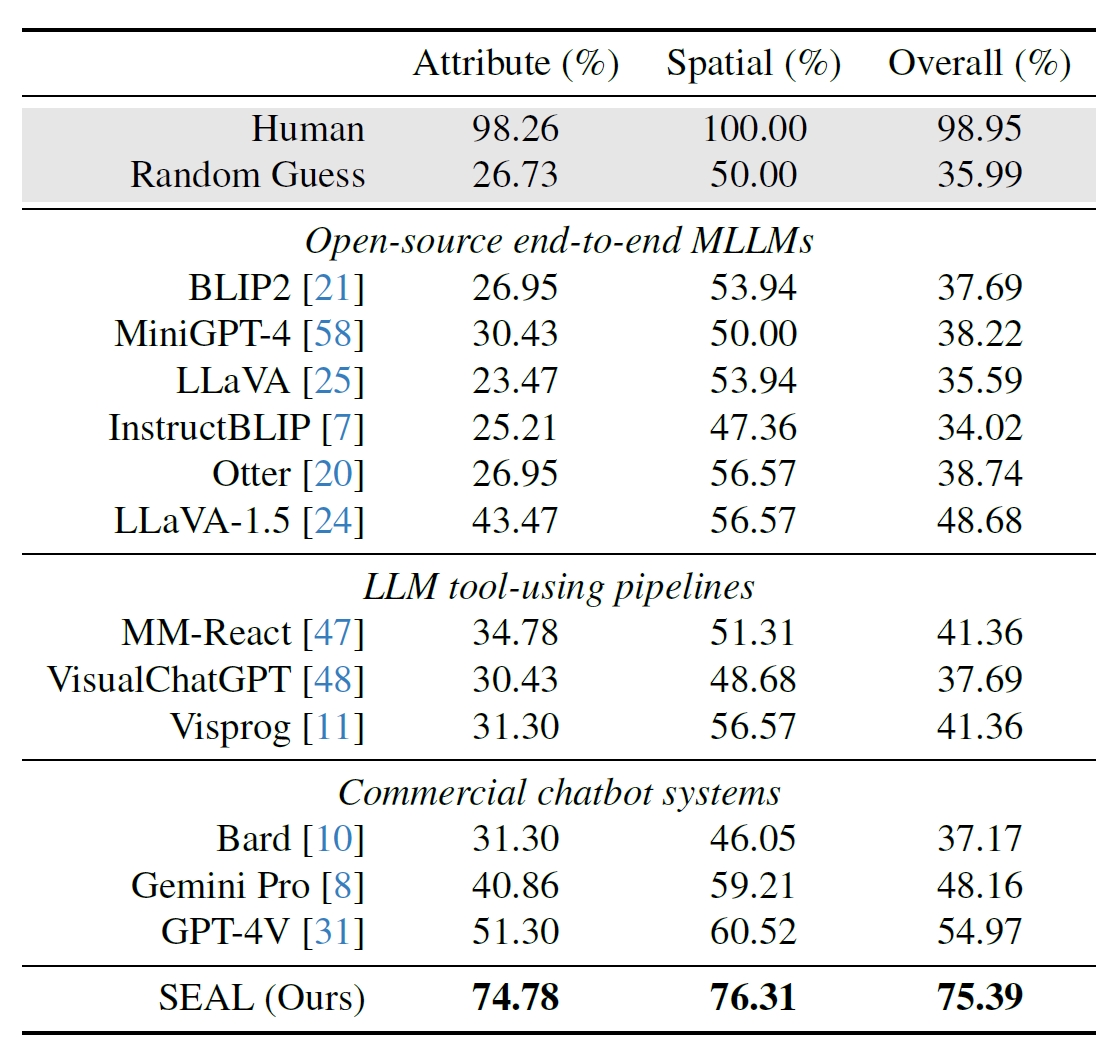
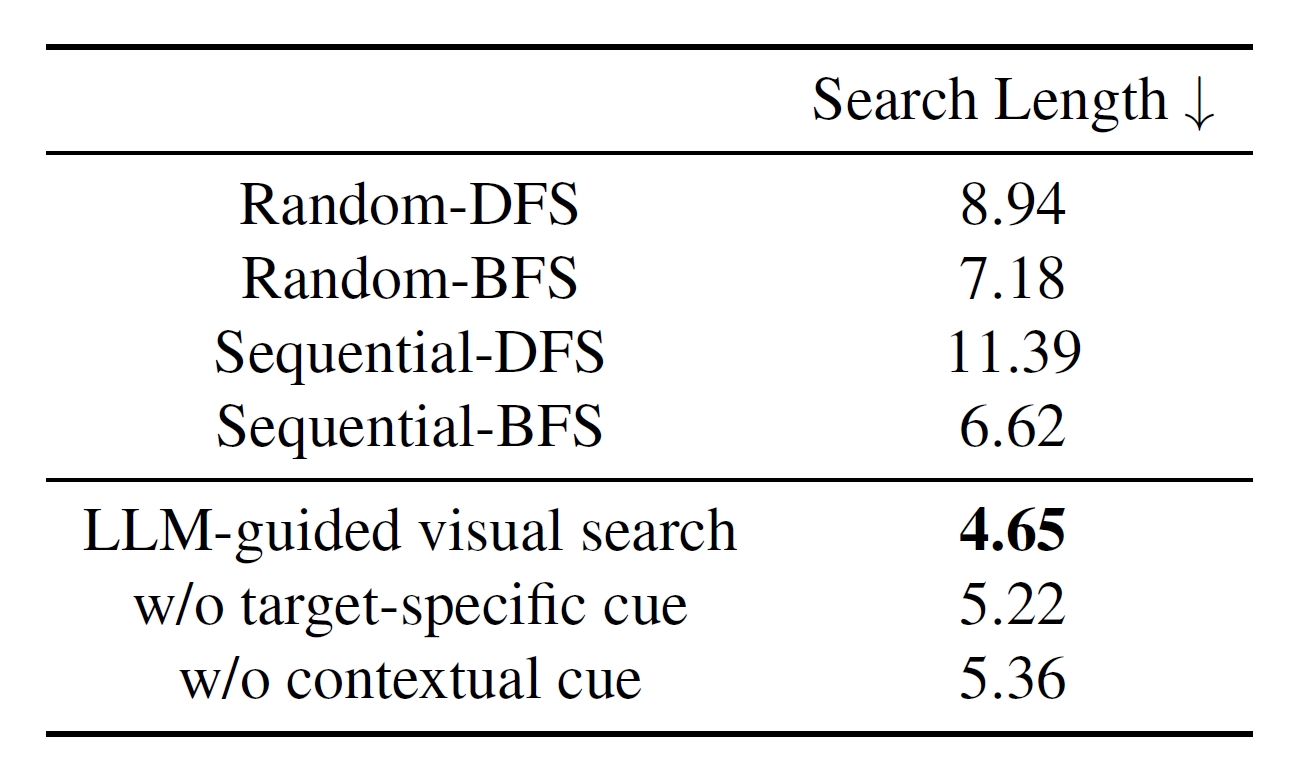
We evaluate different search strategies in terms of search length on 245 target objects in V*Bench. The search length here is defined as the number of search steps from the initial image to the patch where the target is located. We compare our LLM-guided search strategy with two baselines. The random baseline adopts the random strategy to pick a random sub-image to explore, and the sequential baseline searches the sub-images in sequential order. These two strategies are evaluated in breadth-first search (BFS) and depth-first search settings respectively.


@article{vstar,
title={V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs},
author={Penghao Wu and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2312.14135},
}